EigenAI Overview
Overview
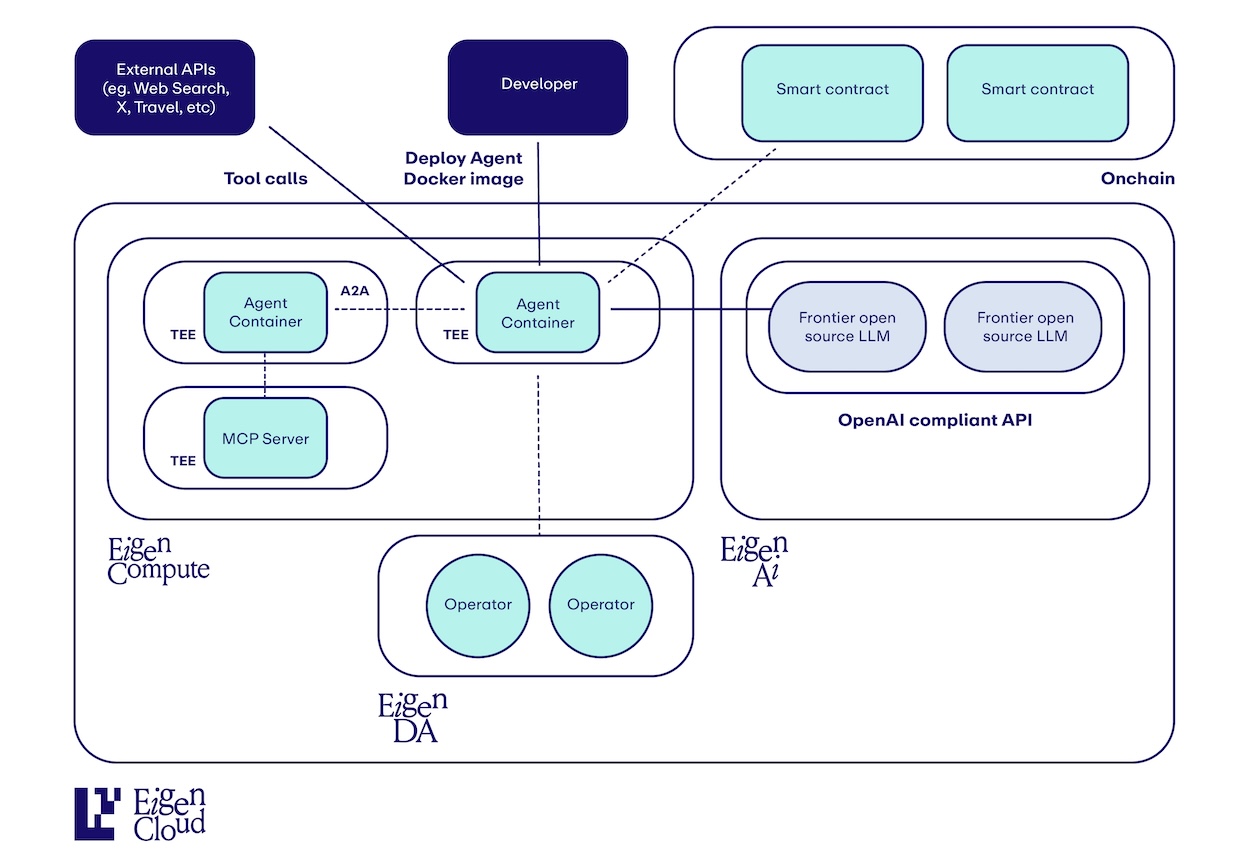
Build verifiable applications leveraging LLM inference without wondering if the same LLM call might produce different results on different runs, or whether your prompts, models, or responses are modified in any way. EigenAI offers a deterministic, verifiable API, compatible with the OpenAI API, so you can simply place the API endpoint in your existing application to start shipping AI-based applications you and your users can trust.
AI is one of the greatest technological advancements in human history. Our mission is to enable any developer to build with scalable & verifiable AI, so that any developer anywhere in the world can build trusted applications.
Use Cases
Builders are leveraging EigenAI to build applications such as:
- Prediction Market Agents: Build agents who can interpret real world events, news, etc and place bets or dispute market settlements.
- Trading Agents: Build agents who can reason through financial data with consistent quality of thinking (no need to worry if models are quantized or not in production) while you ensure they process all of the information they're given (unmodified prompts) and that agents actually use the unmodified responses. You can also ensure they reliably make the same trading decision if prompted about the same data multiple times (via EigenAI's determinism).
- Verifiable AI Games: Build games with AI characters or AI governance, where you can prove to your users that their interactions with the AI aren't being gamed.
- Verifiable AI Judges: Whether it's contests / games, admissions committees, or prediction market settlements, AI can be used to verifiably judge entries / submissions.
Get started
A few key points:
- By OpenAI compliancy we specifically mean the messages-based Chat Completions API: https://platform.openai.com/docs/api-reference/chat/create
- By “deterministic” we specifically mean that one request (prompt, parameters, etc) provided to the API multiple times will produce the same output bit-by-bit, compared to the potentially varying responses one would typically get if calling an OpenAI, Anthropic, etc endpoint as they do not guarantee deterministic behavior. We will be releasing more details shortly on how EigenAI achieves this across the stack.
- On wanting non-determinism:
- You can still introduce non-determinism in your application if you want. By setting a different seed for requests but otherwise keeping the request the same, the API will produce a different output.
- On verification: As part of EigenAI’s mainnet alpha release, the code will be open sourced shortly after. Anyone with access to commodity GPUs will be able to leverage the determinism of EigenAI's software to re-execute any requests and verify the responses given to them by EigenAI.
- As we go towards general availability, we will stand up another API that can be used for this verification flow.
Usage
We're starting off with supporting the gpt-oss-120b-f16 model based on initial demand and expanding from there. To get started or request another model, visit our onboarding page.
$ curl -X POST https://eigenai.eigencloud.xyz/v1/chat/completions \
-H "X-API-Key: <api-key>" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-oss-120b-f16",
"max_tokens": 120,
"seed": 42,
"messages": [{"role": "user", "content": "Write a story about programming"}]
}' | jq
{
"id": "chatcmpl-eigenai-llama-1758835890305965",
"created": 1758835890,
"model": "gpt-oss-120b-f16",
"system_fingerprint": "eigenai-llama@0.1.0+eigenai-llama",
"object": "chat.completion",
"usage": {
"completion_tokens": 120,
"prompt_tokens": 72,
"total_tokens": 192
},
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "<|channel|>analysis<|message|>The user asks: \"Write a story about programming\". Need to produce a story. Probably creative, about programming, characters, maybe AI, debugging, etc. Should be engaging. No constraints other than story. I will craft a narrative with a protagonist, their journey, maybe metaphorical. Use vivid language. Provide a story. Ensure it's appropriate. Probably around 800-1200 words? Not too long, but enough. I'll deliver.<|end|><|start|>assistant<|channel|>final<|message|>**The Compiler’s Apprentice**\n\nWhen Maya first walked into the cramped, fluorescent‑lit office of LumenTech"
},
"finish_reason": "length"
}
],
"signature": "2ee2e48ae9f6796c1de67977981d937c886efec3957c9bfc28f7a3f3be8262f04af609f22878b3bc2f0c4858fd04005d76877208881abd473208317df1dcfaf11c"
}
OpenAI Client usage
from openai import OpenAI
client = OpenAI(
base_url="https://eigenai.eigencloud.xyz/v1",
default_headers={"x-api-key": api_key}
)
tools: List[Dict[str, Any]] = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
},
}
]
step1 = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "What is the weather like in Boston today?"}],
tools=tools,
tool_choice="auto",
)
"""
Response:
{
"id": "chatcmpl-eigenai-llama-1758836092182536",
"object": "chat.completion",
"created": 1758727565,
"model": "gpt-oss-120b-f16",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_YDzzMHFtp1yuURbiPe09uyHt",
"type": "function",
"function": {
"name": "get_current_weather",
"arguments": "{\"location\":\"Boston, MA\",\"unit\":\"fahrenheit\"}"
}
}
],
"refusal": null,
"annotations": []
},
"finish_reason": "tool_calls"
}
],
"usage": {
"prompt_tokens": 81,
"completion_tokens": 223,
"total_tokens": 304,
"prompt_tokens_details": {
"cached_tokens": 0,
"audio_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 192,
"audio_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
},
"""
messages_step2: List[Dict[str, Any]] = [
{"role": "user", "content": "What is the weather like in Boston today?"},
{
"role": "assistant",
"content": None,
"tool_calls": [
{
"id": tool_call_id,
"type": "function",
"function": {
"name": "get_current_weather",
"arguments": json.dumps({"location": "Boston, MA", "unit": "fahrenheit"}),
},
}
],
},
{"role": "tool", "tool_call_id": tool_call_id, "content": "58 degrees"},
{"role": "user", "content": "Do I need a sweater for this weather?"},
]
step2 = client.chat.completions.create(model=model, messages=messages_step2)
"""
Response
{
"id": "chatcmpl-eigenai-llama-CJOZTszzusoHvAYYrW8PT5lv6vzKo",
"object": "chat.completion",
"created": 1758738719,
"model": "gpt-oss-120b-f16",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "At around 58°F in Boston you’ll feel a noticeable chill—especially if there’s any breeze or you’re out in the morning or evening. I’d recommend throwing on a light sweater or layering a long-sleeve shirt under a casual jacket. If you tend to run cold, go with a medium-weight knit; if you’re just mildly sensitive, a thin cardigan or pullover should be enough.",
"refusal": null,
"annotations": []
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 67,
"completion_tokens": 294,
"total_tokens": 361,
"prompt_tokens_details": {
"cached_tokens": 0,
"audio_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 192,
"audio_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
},
"""
Supported parameters
This list will be expanding to cover the full parameter set of the Chat Completions API.
messages: array- A list of messages comprising the conversation so far
model: string- Model ID used to generate the response, like
gpt-oss-120b-f16
- Model ID used to generate the response, like
max_tokens: (optional) integerseed: (optional) integer- If specified, our system will run the inference deterministically, such that repeated requests with the same
seedand parameters should return the same result.
- If specified, our system will run the inference deterministically, such that repeated requests with the same
stream: (optional) bool- If set to true, the model response data will be streamed to the client as it is generated using Server-Side Events (SSE).
temperature: (optional) number- What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic.
top_p: (optional) number- An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered.
logprobs: (optional) bool- Whether to return log probabilities of the output tokens or not. If true, returns the log probabilities of each output token returned in the
contentofmessage
- Whether to return log probabilities of the output tokens or not. If true, returns the log probabilities of each output token returned in the
frequency_penalty: (optional) number- Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model's likelihood to repeat the same line verbatim.
presence_penalty: (optional) number- Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model's likelihood to talk about new topics.
tools: array- A list of tools (function tools) the model may call.
tool_choice: (optional) string- “auto”, “required”, “none”
- Controls which (if any) tool is called by the model.
nonemeans the model will not call any tool and instead generates a message.automeans the model can pick between generating a message or calling one or more tools.requiredmeans the model must call one or more tools. Specifying a particular tool via{"type": "function", "function": {"name": "my_function"}}forces the model to call that tool. noneis the default when no tools are present.autois the default if tools are present.